
インターネット上には専門分野に特化した用語集が多く公開されており、翻訳作業の中でその業界や分野で使用される用語を理解するために、良く利用されていると思います。ただ、インターネット上にあることで検索性が乏しく、PC内にある辞書と同じように簡単に検索出来たらと考えるのは、翻訳を仕事にしている人間なら当然のことでしょう。
私が良くやるのは、それらのウエブ用語集を変換してWildLight用辞書にしてしまうという方法です。一度変換しておけば、他への流用もできますからとても有益な作業なのですが、ただ、それを簡単に実現する方法がありませんよね?
私もいろいろな方法を使っていますが、1つの方法としてWildLightを使う方法です。
今回は、その方法の一例をご紹介します。
今回、題材にあげるのは統計用語集(http://software.ssri.co.jp/statweb2/gloss/glossary.html) です。この用語集を例にした理由は、通常、公開されている用語集には表形式が多く、それらはどちらかといえば変換が容易な形式ですが、この統計用語集は日本語と英語が複数行に跨いでおり、変換が難しいと思われたからです。
こういったウエブ用語集は、その作り方により、変換が可能なものとそうでないものに分かれますが、表示される画面のソースを見て判断することになります。今回は、以下のようなアプローチで変換を試みます。
- ソースファイルを読み解く。
- 変換するための作戦を決める。
- ワイルドカードとWildLight特殊コマンドを記述する。
1.ソースファイルを読み解く
統計用語集の「ア行」を表示し、ブラウザ上で右クリックしてソースを表示します。すると、こんな記述がみられます。
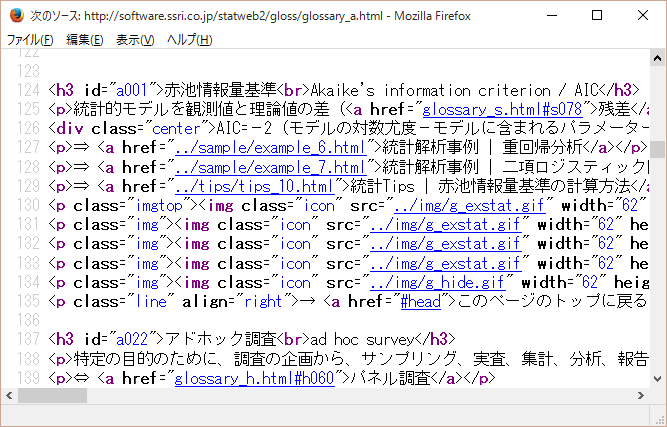
この場合、用語集として必要になるのは日本語と英語のペアですが、ソースファイルを上から下まで眺めていくと、どうも、この用語ペアは以下のような記述になっているようです。
<h3 id=”a022″>アドホック調査<br>ad hoc survey</h3>
2.変換するための作戦を決める
ソースを良く見て、すべてが以下のような構成になっているかを確認します。「<h3 id=”????”>」や「<br>」「</h3>」が他に使用されていないかもあわせて確認します。
<h3 id=”????”>検索語<br>置換語</h3>
他の読み行のソースも含めて確認し、すべてこの構成で成り立っていて、かつ、他に使用されていないことが確認できました。では、以下の作戦でやってみましょう。
- 「<h3 」で始まるタグを用語ペアの先頭(3の後ろには半角スペースがあります)
- 「<br>」をセパレータ
- 「</h3>」を用語ペアの終端
これらの条件で用語ペアの検索を掛けて、対象に蛍光ペン付けし、WildLightの特殊コマンド ExtractH2Word で蛍光ペン部をワードへ抜き出します。
1回の作業で用語集ができそうな感じに見えますが、実は、<br>をタブに変換した後に特殊コマンド(ExtractH2Word)でワードへ抽出した場合、タブが消えてしまうという制限があるため、2段階で作業をする必要があります。つまり、まず、1)用語ペアを抜き、それから2)セパレータをタブへ置換する、という流れになります。
3.ワイルドカードとWildLight特殊コマンドを記述する
用語ペアの抜き出しの記述を考える前に、用語ペアを抜いた後の処理を少し意識しておきたいと思います。それは、今後もいろいろな形式の用語集を変換することになると想像され、二度目の処理としてセパレータの置換が必ず発生するわけですから、できれば毎回同じWildLight辞書で処理できるように、最初の処理である「用語ペア抜き」の結果が、いつも同じスタイルになるようにルールを決めておきたいと思います。
そのルールとは、用語ペアは「●」で囲み、セパレータは「■」とするスタイルです。
では、今回のケースでも、抜き出し結果がこのスタイルになるように用語ペアを抜いてみます。
- 「<h3 」で始まるタグを「●」に変換
- 「<br>」を「■」に変換
- 「</h3>」を「●」に変換
次に、作業の流れを作ります。
- 蛍光ペンを付けずに、「<h3 」で始まるタグを「●」に変換
- 蛍光ペンを付けずに、「<br>」を「■」に変換
- 蛍光ペンを付けずに、「</h3>」を「●」に変換
- 「●」と「●」に挟まれた文字列へ蛍光ペンを付ける。
- 蛍光ペン部を新文書へ抽出する。
この流れにより、「●検索語■置換語●」というスタイルで用語ペアが抽出されることになります。では、具体的にワイルドカードと特殊コマンドで記述してみます。
- WILDCARD:ON
まず、ワイルドカードが利用できるようにONにします。 - ~\<h3 *\>(tab)●
置換後の文字に蛍光ペンを付けないため、先頭に「~」を付与し、検索語「\<h3 *\>」を記述します。(「<」や「>」などのワイルドカード文字を検索語とするときは、その前に「\」を付けなくてはなりません。)
そしてセパレータのタブを入れ、置換語の「●」を記述します。 - ~\<br\>(tab)■
同様に蛍光ペンなしの「~」を先頭に入れて、検索語「\<br\>」を記述し、セパレータのタブを入れて、置換語の「■」を記述します。 - ~\<\/h3\>(tab)●
同様に蛍光ペンなしの「~」を先頭に入れて、検索語「\<\/h3\>」を記述し、セパレータのタブを入れて、置換語の「●」を記述します。 - ●*●
●で挟まれた文字列をすべて蛍光ペン付けします。 - ExtractH2Word
蛍光ペンがついた文字列をワードへ新規文書として抽出します。
これらを記述した辞書を作成し、統計用語集のア行のソースに適用してみます。
(「WLDIC_Sample_抽出_統計用語集.txt」としてWildLight Dic Library に登録しておきましたので、ご覧ください)
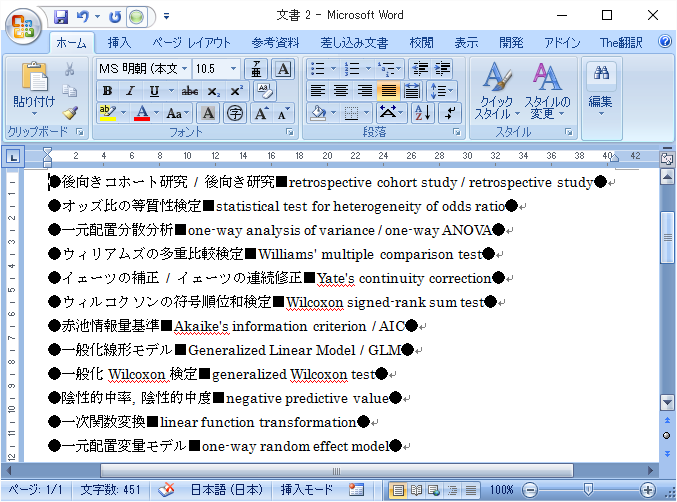
上手く用語ペアが抽出できたようです。あとは、最後の料理として、「●」を消し、「■」をタブに置き換えます。そのための記述は以下のようになります。
- WILDCARD:ON
ワイルドカードが利用できるようにONにします。 - ~●(*)●(tab)\1
置換結果に蛍光ペンが付かないよう先頭に「~」を付与し、「●」で挟まれた文字列を検索して、「●」を除いた文字列へ置き換えます。 - ~■(tab)^t
置換結果に蛍光ペンが付かないよう先頭に「~」を付与して「■」を検索し、タブ(^t)へ置換します。
これらを記述した辞書ファイルを「WLDIC_変換_●■●記述を辞書へ変換する.txt」として登録してありますので、ご利用ください。(今後、「●検索語■置換語●」スタイルで用語ペアを抽出すれば、この辞書を流用できます)
この辞書を、上記の抽出結果に適用すると、以下のようになります。

この作業を各「読み行」で実施し、変換された用語ペアを合体すれば、WildLight辞書の出来上がりです。
こんなやり方で、ウエブに公開されているいろいろな用語集を変換してみると良いと思います。
