日本語文書から用語集候補文字列を抽出するWildLight辞書を以前公開しましたが、今回は英語文書から用語集候補の単語もしくは連語を抽出する辞書です。
以前、某社で行ったWildLightセミナーの中で、その抽出方法の考え方をお伝えした事があり、その際「いつ出来ますか?」と質問を受けていながら、長らく放置していました。
以下がそのWildLight 用辞書です。WildLight Library に登録されています。
WLDIC_抽出_英文から用語集候補をエクセルへ抜く.txt
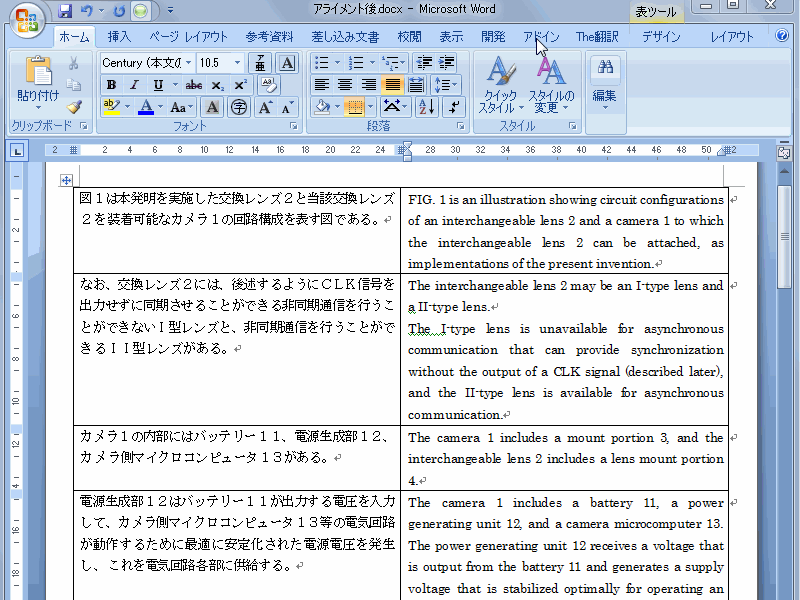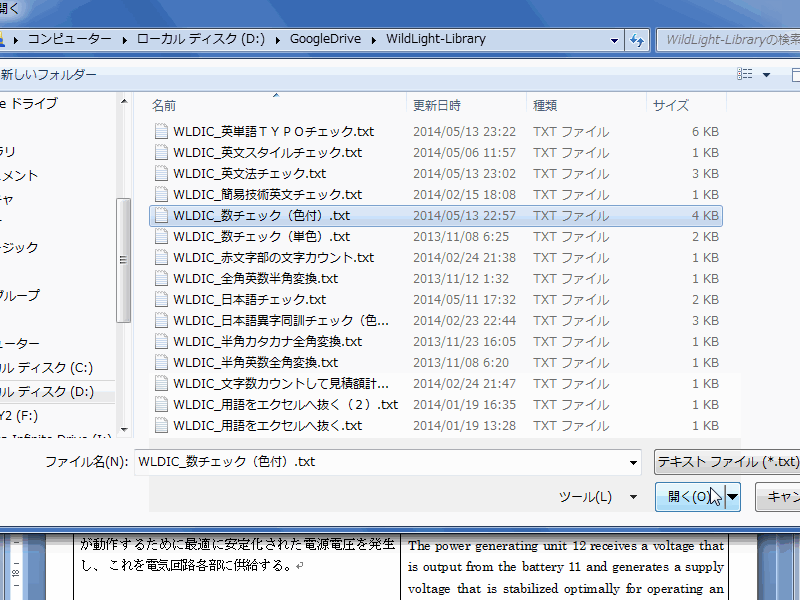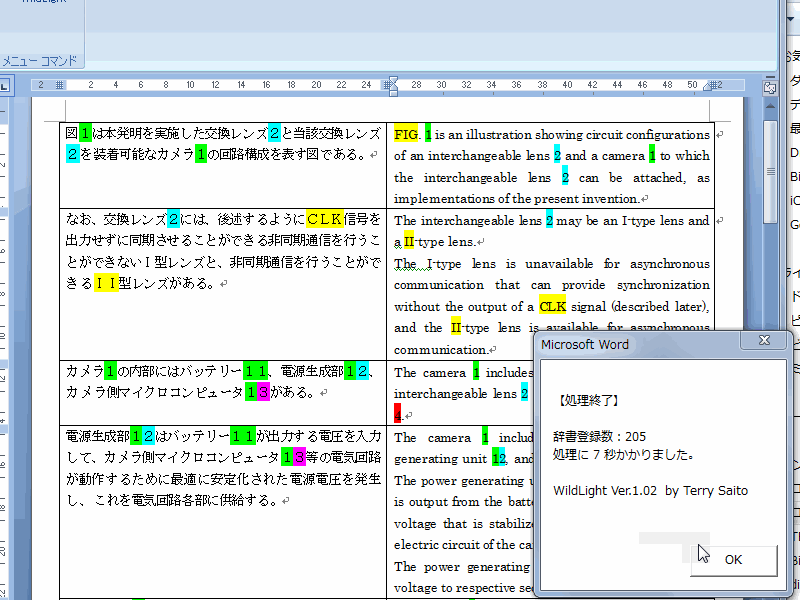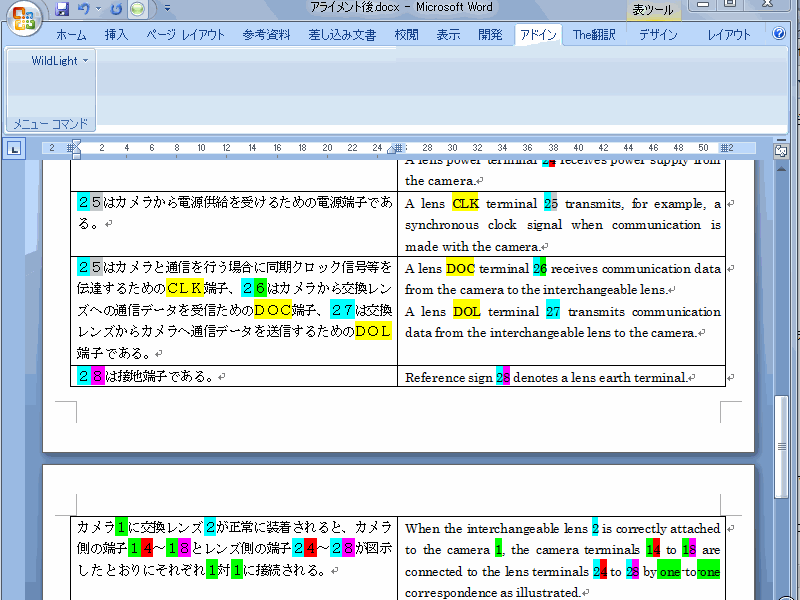
この辞書で行っていることは、以下のような文字列を検索し、蛍光ペン付けをしてテキスト抽出しています。
- 頭文字が大文字で始まる単語
- その単語が連続した連語
具体的にどういうものか? 上記の1「頭文字が大文字で始まる単語」とは、Hello とか HELLO のような単語です。2「その単語が連続した連語」とは、Hello World とか HELLO World など、頭文字が大文字で始まる単語のセットのことです。
用語集候補は、例えば「Microsoft Visual Basic」や「National Art Museum」に見られるように、単語の頭文字が大文字になっている単語/連語の場合が多いので、そういう単語を検索して抜いてしまおうと言うのがアイデアです。
辞書の記述は以下の通り。(わかり易くする為にくどい書き方をしています。)
[A-Z&][A-Za-z0-9\-&]{1,}[ ]
[A-Z&][A-Za-z0-9\-&]{1,}
[&][ ]
ExtractH2Excel
1行目は、頭文字がアルファベットの大文字で、それに続く文字列が英数字で、最後が半角スペースのものを検索して蛍光ペンをつけます。
2行目は、頭文字がアルファベットの大文字で、それに続く文字列が英数字のものを検索して蛍光ペンをつけます。
3行目は、半角のアンドマークと半角スペースのセットを検索して蛍光ペンをつけます。
1行目と2行目は記述が似ています。違いは終端の半角スペースだけです。1行目で、殆どの単語と連語が蛍光ペン付けされますが、文末にある単語は残ってしまいます。それを2行目の記述で蛍光ペン付けします。
何故こんなやり方をしているかと言うと、改行を抽出対象としない為です(抽出されなくなる)
3行目は、単語が&で繋がれている連語を、連語として抽出する為に検索して蛍光ペン付けします。
この辞書ではあくまでも「候補」の抽出しかできません。お分かりの通り、文頭の単語は無条件で抽出対象となります(頭文字が大文字だから)。
抽出された単語/連語を自分の目で見て、不要物を除去して下さい。面倒だと思われる方は、例えば潔く連語だけを残すと言う考え方もあります(用語集に盛り込むべき連語の可能性が高い)。
この辞書の記述はひとつの例でしかありませんので、皆さんの使途に合わせて変えて使ってみて下さい。
[テキスト抽出のポイント]
抽出対象の検索は、ワイルドカードを一文で表現する必要はありません。抽出部位を別々に検索して、蛍光ペン付けするようにします。(これがWildLightの強みです)
蛍光ペンのテキスト抽出機能は、蛍光ペンが付いている連続した文字列を1つの塊として抜き出します。従って、別々に検索して色付けされても、最終的に蛍光ペンでひと塊りになっていれば問題ないのです。