先日、某所でWildLight初級セミナーを行いました。そこで「全角スペースを半角へ変換する方法」の質問を受けましたので、WildLight辞書の記述方法を記しておきます。
' ワイルドカードモードにする WILDCARD:ON ' 全角スペースに蛍光ペンを付ける(変換箇所が分かるように) [ ] Zen2Han,[ ]
辞書ファイル「WLDIC_変換_全角スペースを半角へ変換.txt」としてWildLight共有フォルダーに公開しておきましたので、ダウンロードしてご利用ください。

先日、某所でWildLight初級セミナーを行いました。そこで「全角スペースを半角へ変換する方法」の質問を受けましたので、WildLight辞書の記述方法を記しておきます。
' ワイルドカードモードにする WILDCARD:ON ' 全角スペースに蛍光ペンを付ける(変換箇所が分かるように) [ ] Zen2Han,[ ]
辞書ファイル「WLDIC_変換_全角スペースを半角へ変換.txt」としてWildLight共有フォルダーに公開しておきましたので、ダウンロードしてご利用ください。
先日行ったWildLight中級セミナーで、受講していただいた方から以下のようなお題をいただきました。もちろん、セミナーではこれを題材にワイルドカードとWildLight特殊コマンドの実習を行いました。うまく解決できたお題ですので、当ブログでシェアいたします。
4桁以上の数字を自動的にカンマで位取りしたい
まず考えたいのは、対象となる数字の桁数です。4桁以上は確かですが、最大何桁までを対象と考えるかです。
X,XXX 〜 XXX,XXX,XXX,XXX
まぁ「兆」くらいをカバーしておけば実用的でしょうか?(笑) すると対応しなくてはならない組合せは以下の3通りということになります。
XXX,XXX
XXX,XXX,XXX
XXX,XXX,XXX,XXX
ワイルドカードで実現する上で、数字の桁数によって処理を変えるというのは、記述が難しそうですので、まずは、末尾三桁(下の例だと012)とそれ以前(123456789)を分けてヒットさせる方法を考えました。
123456789012
[0-9]@[0-9]{3}>
このワイルドカードの記述により、末尾三桁を[0-9]{3}> でヒットさせ、それ以前を [0-9]@ でヒットさせられます。それぞれを置換時に利用するために ( ) で括り、そして、それらの間に位取りのカンマ「,」を挿入するために、置換語に「¥1,¥2」と記述すれば良いことになります。WildLight辞書へは以下のように記述します。(※(TAB)は実際にタブキーを押して入力してください)
WILDCARD:ON
([0-9]@)([0-9]{3})>(TAB)¥1,¥2
この辞書を実行すると、4桁以上の数字は、以下のようになるはずです。
123,456
123456,789
123456789,012
さて、さらに上位の桁の位取りはどうしたらいいでしょう?
そうです。このワイルドカードを繰り返して実行すればいいのです。
ただし、ここで注意しなければならないのは、WildLightに以下の基本機能があることです。
上記のワイルドカードを実行したことにより、数字にはすべて蛍光ペンがついている状態になっています。つまり、そのまま続けて実行したのでは、それらの数字は検索対象から除外されてしまい、位取りがされません。そこで利用するのが、検索時の蛍光ペンの有無を無視するコマンド「IgnoreH」です。
IgnoreH:ON で、検索時に蛍光ペンの有無を無視します(すべてを検索対象として検索する)。ちなみに IgnoreH:OFF でデフォルト値に戻り、基本機能通り、蛍光ペン箇所は検索対象から除外されます。では、これを使って辞書を記述してみると以下の通りになります。
WILDCARD:ON
([0-9]@)([0-9]{3})>(TAB)¥1,¥2
IgnoreH:ON
([0-9]@)([0-9]{3})>(TAB)¥1,¥2
([0-9]@)([0-9]{3})>(TAB)¥1,¥2
これで、兆までの数字に対して3桁位取りが自動で行われ、蛍光ペンがつきます。
この辞書は、ライブラリーに「WLDIC_変換_4桁以上の数値をカンマで自動的に位取り.txt」という名前で登録してありますので、ダウンロードしてご利用ください。
WildLightは、ワイルドカードの1文では表現しきれない処理も、辞書に記述を並べることで処理を可能にできるところが、大きな特長です。
インターネット上には専門分野に特化した用語集が多く公開されており、翻訳作業の中でその業界や分野で使用される用語を理解するために、良く利用されていると思います。ただ、インターネット上にあることで検索性が乏しく、PC内にある辞書と同じように簡単に検索出来たらと考えるのは、翻訳を仕事にしている人間なら当然のことでしょう。
私が良くやるのは、それらのウエブ用語集を変換してWildLight用辞書にしてしまうという方法です。一度変換しておけば、他への流用もできますからとても有益な作業なのですが、ただ、それを簡単に実現する方法がありませんよね?
私もいろいろな方法を使っていますが、1つの方法としてWildLightを使う方法です。
今回は、その方法の一例をご紹介します。
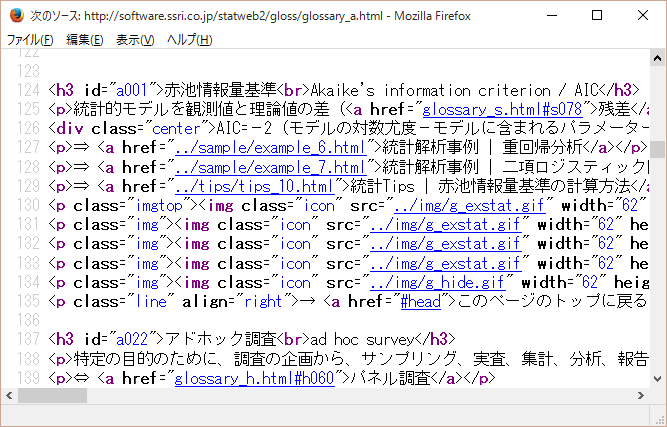
今回、題材にあげるのは統計用語集(http://software.ssri.co.jp/statweb2/gloss/glossary.html) です。この用語集を例にした理由は、通常、公開されている用語集には表形式が多く、それらはどちらかといえば変換が容易な形式ですが、この統計用語集は日本語と英語が複数行に跨いでおり、変換が難しいと思われたからです。
こういったウエブ用語集は、その作り方により、変換が可能なものとそうでないものに分かれますが、表示される画面のソースを見て判断することになります。今回は、以下のようなアプローチで変換を試みます。
1.ソースファイルを読み解く
統計用語集の「ア行」を表示し、ブラウザ上で右クリックしてソースを表示します。すると、こんな記述がみられます。
この場合、用語集として必要になるのは日本語と英語のペアですが、ソースファイルを上から下まで眺めていくと、どうも、この用語ペアは以下のような記述になっているようです。
<h3 id=”a022″>アドホック調査<br>ad hoc survey</h3>
2.変換するための作戦を決める
ソースを良く見て、すべてが以下のような構成になっているかを確認します。「<h3 id=”????”>」や「<br>」「</h3>」が他に使用されていないかもあわせて確認します。
<h3 id=”????”>検索語<br>置換語</h3>
他の読み行のソースも含めて確認し、すべてこの構成で成り立っていて、かつ、他に使用されていないことが確認できました。では、以下の作戦でやってみましょう。
これらの条件で用語ペアの検索を掛けて、対象に蛍光ペン付けし、WildLightの特殊コマンド ExtractH2Word で蛍光ペン部をワードへ抜き出します。
1回の作業で用語集ができそうな感じに見えますが、実は、<br>をタブに変換した後に特殊コマンド(ExtractH2Word)でワードへ抽出した場合、タブが消えてしまうという制限があるため、2段階で作業をする必要があります。つまり、まず、1)用語ペアを抜き、それから2)セパレータをタブへ置換する、という流れになります。
3.ワイルドカードとWildLight特殊コマンドを記述する
用語ペアの抜き出しの記述を考える前に、用語ペアを抜いた後の処理を少し意識しておきたいと思います。それは、今後もいろいろな形式の用語集を変換することになると想像され、二度目の処理としてセパレータの置換が必ず発生するわけですから、できれば毎回同じWildLight辞書で処理できるように、最初の処理である「用語ペア抜き」の結果が、いつも同じスタイルになるようにルールを決めておきたいと思います。
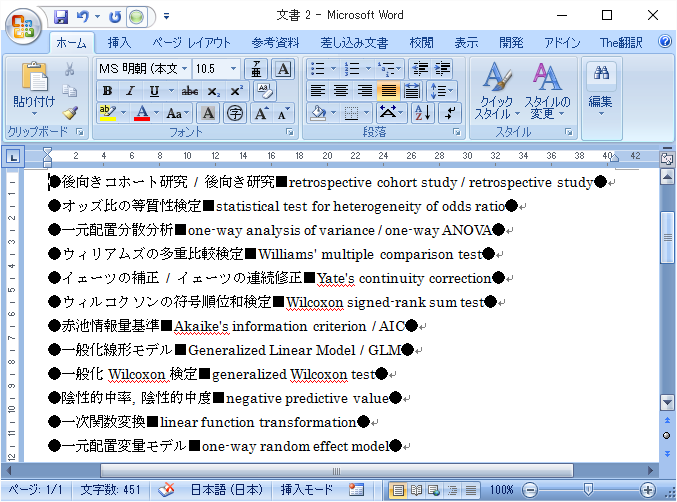
そのルールとは、用語ペアは「●」で囲み、セパレータは「■」とするスタイルです。
では、今回のケースでも、抜き出し結果がこのスタイルになるように用語ペアを抜いてみます。
次に、作業の流れを作ります。
この流れにより、「●検索語■置換語●」というスタイルで用語ペアが抽出されることになります。では、具体的にワイルドカードと特殊コマンドで記述してみます。
これらを記述した辞書を作成し、統計用語集のア行のソースに適用してみます。
(「WLDIC_Sample_抽出_統計用語集.txt」としてWildLight Dic Library に登録しておきましたので、ご覧ください)
上手く用語ペアが抽出できたようです。あとは、最後の料理として、「●」を消し、「■」をタブに置き換えます。そのための記述は以下のようになります。
これらを記述した辞書ファイルを「WLDIC_変換_●■●記述を辞書へ変換する.txt」として登録してありますので、ご利用ください。(今後、「●検索語■置換語●」スタイルで用語ペアを抽出すれば、この辞書を流用できます)
この辞書を、上記の抽出結果に適用すると、以下のようになります。
この作業を各「読み行」で実施し、変換された用語ペアを合体すれば、WildLight辞書の出来上がりです。
こんなやり方で、ウエブに公開されているいろいろな用語集を変換してみると良いと思います。
以前、サンフレアアカデミーのオープンスクールでWildLightの説明をした際に、「蛍光ペンのついた文字列をワードやエクセルへ抜き出せるか?」という質問をいただき、「SFAオープンスクールの質問から」という記事にまとめていますが、改めて別記事として公開しておきます。
ワード文書中の蛍光ペンがついたテキストを抽出できると、ちょっと便利な使い方ができますよね。
例えば、用語集用に必要な単語や表現に蛍光ペンを付けておき、最後にそれらを抽出して用語集にするといった使い方ができます。事実、サンフレアアカデミーのオープンスクールでいただいた質問の目的は、用語集作成に使用したいということでした。
まず、特別な知識なく実現できるように、辞書ファイルを準備してあります。
エクセルへ抜きたい時は1の辞書、ワードへ抜き出したい時は2の辞書を使います。目的に合わせて辞書ファイルをダウンロードし、WildLightで適用してみてください。用語集作成を目的としているなら、いきなりエクセルへテキストを抜いてしまうと便利かもしれませんね。
では、実際にやってみた映像をこちらに張り付けておきます。(これは「WLDIC_抽出_蛍光ペン部をExcelへ抜く.txt」を適用したケースです。)

うっかり同じ単語を蛍光ペンしていても大丈夫です。ユニークなものだけを抽出する仕様になっています。(「あれ?これ、さっき色付けたっけ?」なんて、悩まなくて大丈夫。気にしないでどんどん蛍光ペン付けしちゃいましょう)
さて、ここからは中級者/上級者の方への説明です。
蛍光ペンのテキストを抜き出す機能は、以下のWildLightの特殊コマンドで実現できます。
前者がエクセルへ抽出、後者がワードへ抽出するための特殊コマンドです。ワイルドカードとの組み合わせで、意図した文字列を抜き出すことができるようになります。例えば、全角カタカナの用語だけを抜き出したい場合は、以下のような記述をした辞書を準備すると良いでしょう。
1行目は、ワイルドカードモードをONにします。そして2行目に全角カタカナを指定するワイルドカードを記述することで、全角カタカナすべてに蛍光ペンを付けます。そして最後に、それら蛍光ペンが付いた文字列をエクセルへ抽出するために、特殊コマンド ExtractH2Excel を記述します。
2行目のワイルドカードを工夫することで、いろいろな文字列を抜き出すことが可能になります。
例えば、上記ケースでは1文字のカタカナも抽出されます。それでは都合が悪いなぁ、せめて3文字以上のカタカナだけにして欲しいなぁと考えるなら、2行目を以下の記述にすればOKです。
[ァ-ヾ]{3,}
また、もし、5文字の全角カタカナの用語だけを抽出したい!という場合は、以下のようになります。
[ァ-ヾ]{5}
ここまで読まれた方は、ExtractH2Excel, ExtractH2Word がいろいろなことに応用できそうだと感じたことでしょう。実際、WildLight Dictionary Library に登録してある「WLDIC_抽出_和文から用語集候補をExcelへ抜く.txt」では、この特殊コマンドを使って、和文から用語集候補となる単語をエクセルへ抽出しています。
上記の2行目に当たる部分に、以下の記述をしています。
まず、用語集に必要となる用語には、定訳が存在しそうなものを対象としたいですが、『』や「」内の文字列にはその対象となるものが多いので、『』「」内の文字列を抜くように蛍光ペン付けをしてやります。ただ、そのまま抜いてしまうと『』「」が残ってしまいますので、蛍光ペンを付けつつ、それらの括弧を削除してしまいます。そのための記述が1~2行目です。((TAB)はタブ記号です)
3行目は、全半角の英数字で始まり、全角カタカナと漢字でなる言葉の塊に蛍光ペンを付けます。といってもイメージできないですよね。例えば、「13G45カード基板」とか「1次入力ターミナル」といった類の文字列に蛍光ペンが付きます。
4行目は、全角カタカナと漢字の後ろに全半角の英数字が付いている文字の塊に蛍光ペンを付けます。例えば「プライマリー電源001」とか「角度ABC」といった類の文字列に蛍光ペンが付きます。
そして最後の5行目は、全角カタカナと漢字の塊に蛍光ペンが付きます。「音量スライダー」とか「スライド軸」といった言葉が対象となります。
なぜ、3段階で蛍光ペン付けをしているかといえば、[全角カタカナと漢字]の塊に先に蛍光ペンを付けてしまうと、[全角カタカナと漢字]の前後に全半角英数文字を持つ文字列の検索手段を失ってしまうからです。(蛍光ペンがついているものは検索対象から外れるというWildLightの制限があるため)
少し複雑な検索をして蛍光ペンを付ける場合は、このように、その順番にも注意が必要です。
(このあたりの話は、以前の記事「日本語原稿から簡易的に用語を抜く」にも書いてあります。)
他にもいろいろな応用ができそうですね。
是非、お役立てください。
こういう単純な作業はWildLightの得意とするところです。
既に、WildLight Dic Library に全角英数字を半角に変換する辞書ファイルが存在しますが、それを加工して、全角数字のみを半角に変換する辞書を作ってみましょう。
まず、全角英数字を半角に変換する辞書ファイルは「WLDIC_変換_全角英数半角変換.txt」です。その中身は以下のようになっています。
1行目は、ワイルドカードモードをONにするための特殊コマンドです。
そして、2行目は何をやっているかというと、半角変換した文字が視覚的に確認できるよう、変換前に変換対象を蛍光ペンで色をつけているのです。これは、全角半角変換、半角全角変換の特殊コマンド (Zen2Han, Han2Zen) では、他のコマンドと違い、処理後に蛍光ペンが付かないという制限があるため、このような2段構えの記述にしています。もし、色付けは不要ということであれば、この行は削除して構いません。
[0-9] で全角数字、[a-zA-Z] で全角英文字です。最後は[.] ピリオドも変換対象にしています。
そして3行目が、全角から半角へ変換する特殊コマンドです。記述すべき検索語は2行目と同じです。
では、全角数字を半角へ変換する辞書を作成するには、どういう記述にしたらいいでしょうか? 簡単ですね。上記の辞書は全角の数字と英文字を対象としていました。つまり、全角数字だけを指定すれば良いことになります。すると、以下のようになりますね。
WILDCARD:ON
[0-9]
Zen2Han,[0-9]
この記述をした辞書を、WildLight Dic Library に登録しておきましたので、お役立てください。辞書名は「WLDIC_変換_全角数字を半角へ変換.txt」です。
今日、ツイッターでお題をいただきました(笑)
Buckeye さん開発の SimplyTerms で抽出したテキストファイルには、以下のような[[と]]で囲まれたタグ情報が付与されます。
[[S1_BD-1]]
翻訳の品質管理とWildLight
[[S1_BD-2]]
@名古屋翻訳者勉強会 2015年1月18日
[[S2_BD-1]]
説明内容
このタグにグレーの蛍光ペンを付与して、見た目が目立たなくしたいというお題でした。これを実現する方法は簡単で、WildLightの特殊コマンドにある HColor コマンドを使用します。このコマンドは、以下のような記述の仕方になります(WildLight取扱説明書参照のこと)
HColor:[色番号],[検索語]
検索語を検索し、色番号で指定された蛍光ペン色を付けます。 (検索語のみ指定色になる)
[色番号]:01:緑, 02:明緑, 03:青緑, 04:濃青, 05:青, 06:水, 07:桃, 08:紫, 09:濃い赤, 10:赤, 11:濃黄, 12:黄, 13:白, 14:25%灰, 15:50%灰, 16:黒
SimplyTerms のタグを検索するには、ワイルドカードを使用します。そして、その検索式(検索語)は以下の形でいいでしょう。注意が必要なのは、[や]を検索語にするときには、その前に\ (¥)が必要です。
[\[]{2}*[\]]{2}
そして、蛍光ペンの色を50%灰色にしてみましょう。その場合、色番号は 15 ということになります。
これらを辞書ファイル(テキストファイル)に記述するわけですが、以下のような記述になります。
WILDCARD:ON
HColor:15,[\[]{2}*[\]]{2}
もちろん、色番号を変えることによって、自分の好きな色に変更できます。塗りつぶしてしまいたいなら、16の黒を使うと良いでしょう。
この記述をした辞書ファイルを作成して WildLight Dic Library に登録しておきましたので、ご利用ください。ファイル名は「WLDIC_作業_SimplyTermsのタグに蛍光ペン付け.txt」です。
ちなみに、WildLightには SimplyTerms のタグを隠し文字属性にして見えなくするメニューが準備されています。(もとに戻すメニューも準備されています) 併せてご利用ください。
今日、以下のような変換をしたいという問合せをもらいました。
英語から和訳を行う際、英語の「FIGURE 1A」とか「FIGURE 10B」を、それぞれ「図 1A」、「図 10B」に変換したいとの事でした。
これをWildLightで変換する場合、ワイルドカードと特殊コマンド Han2Zen を使えば変換できます。
WILDCARD:ON
FIGURE ([0-9A-Z]{1,}) 図 ¥1
Han2Zen,[0-9A-Z]
この3行を記述した辞書ファイルを準備すれば良いです。(2行目の検索語と置換語の間は TABです)
1行目の「WILDCARD:ON」でワイルドカードモードをONにします。
2行目は、検索語に「FIGURE ([0-9A-Z]{1,})」、置換語に「図 ¥1」を指定して置換します。「([0-9A-Z]{1,})」にヒットする図番号が、置換語の「¥1」に代入されて置換されます。
3行目の「Han2Zen,[0-9A-Z]」で半角数字と英大文字を全角文字へ変換します。
お試しください。
昨日、2月28日(土)はサン・フレアアカデミーのオープンスクールでした。
クラスの中でWildLightの使い方に関する質問がありました。これは他の皆さんも利用できる情報ですので、ここにシェアしておきます。
1. 蛍光ペンのついた文字列をワードやエクセルへ抜き出せるか?
WildLight特殊コマンドの「ExtractH2Word」もしくは「ExtractH2Excel」を使います。
例)
ExtractH2Excel
いずれかのコマンドを1行記述した辞書ファイルを準備し、蛍光ペンされたテキストを抜き出したいワード文書へ適用すれば、抜き出せます。
この例を記述した辞書を「WLDIC_抽出_蛍光ペン部をExcelへ抜く.txt」として作成しておきました。ライブラリーからダウンロードしてご利用下さい。
2. PDFファイルからワードにしたものを整形するには、どうしたらいいか?
この質問については明確な回答ができませんでした。PDFからワードファイルを起こした場合、使用したアプリケーションや原稿PDFの中身によって、出る症状が違うからです。
これらへの対処として、以下のような処理を行っています。
' 全角英文字カタカナ漢字の間に挟まった全半角スペースを除去する
([a-zA-Zァ-ヾ一-鶴ぁ-ゞ])[ ]{1,}([a-zA-Zァ-ヾ一-鶴ぁ-ゞ]) \1\2
' 全半角数字の後のスペースを半角スペース1つにする
([0-90-9])[ ]{2,} \1
' 半角英数字間のスペースを半角スペース1つにする
([\!-~])[ ]{1,}([\!-~]) \1 \2
' 文頭の不要なスペースを削除する
^13[ ]{1,} ^p
上記4例とも、[ ]の中は全角スペース1つと半角スペース1つが入っています。
また、セパレーターはTABです。
これらが記述された辞書は、「WLDIC_編集_日本語:PDF抽出文書の成形.txt」として提供しています。
3. エクセルやパワーポイントファイルからテキスト抽出するには、どうしたらいいか?
Microsoft Office Personal以外(Excel, PowerPointが入っているもの)をお使いの方は、WildLight Users Group でのみ配布されている Full バージョンを使えば、エクセルやパワーポイントからテキスト抽出する機能を利用できます。
4. 全角文字の間にまぎれた半角スペースを除去する方法は?
全角文字の間に半角スペースが入っているケースは、PDFファイルからワードへ変換した時に良く見かけるので、質問2への対処の1つとしても有効だと思います。
全角文字をワイルドカードで表現すると以下のようになります。
、-鶴
そして、全角文字に挟まれる半角スペースを検出して削除するには、辞書に次のように記述します。
([、-鶴])[ ]([、-鶴]) \1\2
[ ]の間には半角スペースを入れます。
([、-鶴]) ([、-鶴])と\1\2の間はセパレーターのTABです。
この辞書を「WLDIC_変換_全角文字間の半角スペースを除去.txt」として作成しておきました。ライブラリーからダウンロードしてご利用下さい。
多項式や化学式を記述するのに、上付や下付を多用しますが、その指定を忘れてしまったものを検出する WildLight 辞書の紹介です。
このチェック辞書を作る上で使用する特殊コマンドは「Superscript」と「Subscript」です。
(Users Groupで、この機能実装のアイデアは Kanbayashi さん、以下のチェック方法のアイデアは Yamauchi さんに頂きました。ありがとうございました)
上付も下付も、チェックの手法は同じですので、ここでは下付(Subscript)を例に説明致します。
H2O の2や、CO2の2を下付指定し忘れたものを検出してみましょう。
【考え方】
【辞書の記述方法】
Subscript:OFF H2O CO2 Subscript:CLEAR
1行目は、「下付は検索しないで」という指定です。
2行目から3行目は検索する化学式。ここに検索したい化学式をどんどん追加すれば良い訳です。
4行目で、「下付の検索条件を解除」
これを実際に実行した画像がこれです。(画像をクリックして拡大してご覧ください)
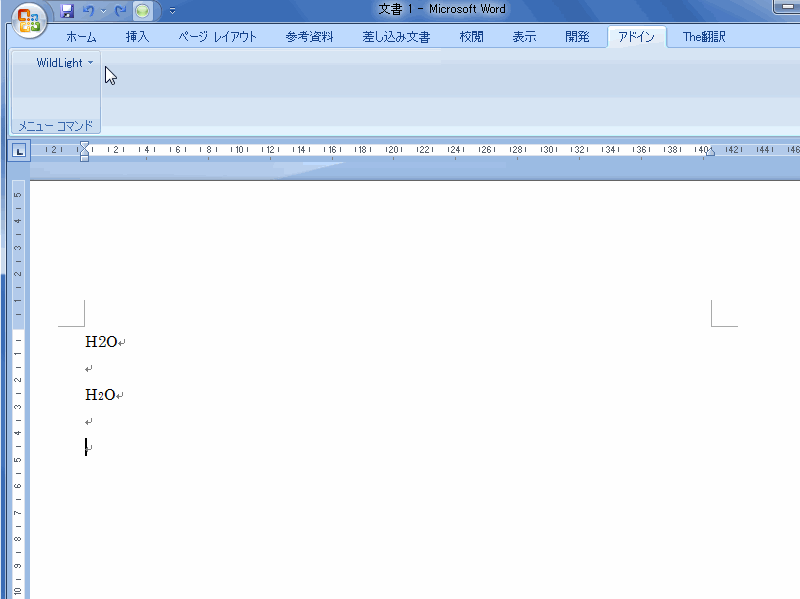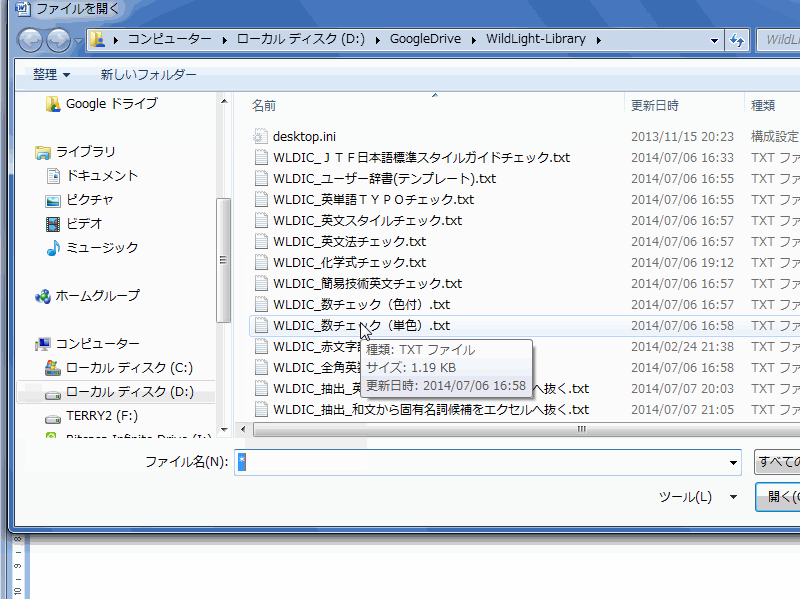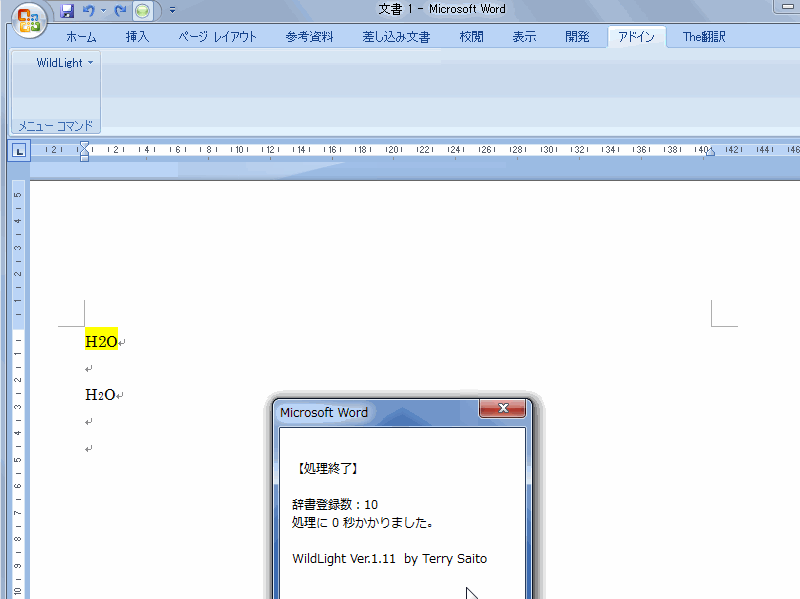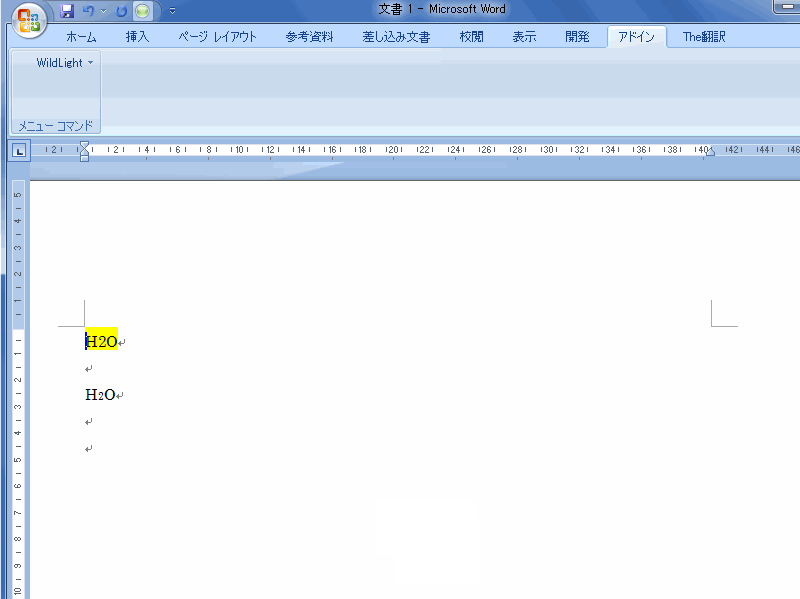
2を下付指定し忘れた H2O に蛍光ペンが付くのが分かると思います。
この辞書は、WildLight Library に「WLDIC_化学式チェック.txt」で登録されていますので、ダウンロードして、ご自身の使用目的に修正してご活用下さい。
英文に続き、今度は和文から用語集候補をエクセルに抜く為の WildLight 辞書です。
過去に「日本語原稿から簡易的に用語を抜く」という記事をアップしていますが、別のアプローチによる抽出です。以下のWildLight辞書をダウンロードして使用して下さい。WildLight Library に登録されています。
WLDIC_抽出_和文から用語集候補をExcelへ抜く.txt
この辞書の記述は以下の通りです。
[『](*)[』] \1
[「](*)[」] \1
[a-zA-Za-zA-Z0-90-9]{1,}[ァ-ヾ一-鶴]{1,}
[ァ-ヾ一-鶴]{1,}[a-zA-Za-zA-Z0-90-9]{1,}
[ァ-ヾ一-鶴]{1,}
ExtractH2Excel
前述の過去記事による用語候補抽出は、5行目の「カタカナと漢字」の文字列だけでしたが、英数字が前後に付くケースも多く見られる事から、3~4行目を追加しました。
英文の抽出と同様、この辞書の適用により抽出された用語も、人間の目で選別を行う必要があります。